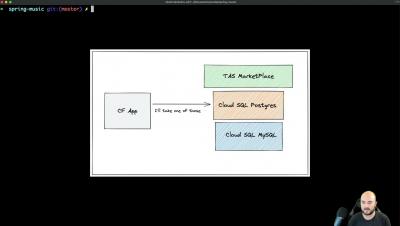
Demo: VMware Tanzu Cloud Service Broker for Google Cloud Platform
Check out this video to see how the Tanzu Cloud Service Broker for Google Cloud Platform can expand your VMware Tanzu Application Service Marketplace.


Hive smart meters revolutionized the way customers control their energy use. But since their launch in 2012 by UK energy company British Gas, advances in cloud technology and a rapid increase in the number of smart homes has led to an explosion of data.
To provide world-class developer experiences and get applications to production quickly and securely, you need a team of experts devoted to running your platform as a product. For organizations that build and publish software at scale, developing the tech stack on which developers will create applications and push them to production is often the main focus.
Scaling data science is hard. From natural language processing for model-driven policy approvals to image classification in biotechnology to supply chain risk and anomaly detection in advanced manufacturing, data science brings tremendous promise—but not without challenges. Only 21 percent of businesses are gaining a major competitive advantage through the use of data and analytics tools, according to a recent survey.
For those managing enterprise software development organizations, the concept of software supply chains—that is, the set of sources and actions that take software from “raw materials” to a finished product—might represent an abstract concept. While this definition is essentially correct, it doesn’t do enough to explain how supply chains can be complementary to your existing continuous integration and continuous deployment (CI/CD) environments.
You can tell the maturity of something by its challenges. For example, the problems of a 27-year-old are different from those of a 47-year-old. In case it’s not clear, this is my attempt at making a relatable analogy to the maturity of Kubernetes. Though, it might be more accurate to say Kubernetes has reached a point of ubiquity; industry analyst research, foundation surveys, and studies including VMware’s 2022 State of Kubernetes report certainly indicate such.
Picture this… You just got your second cup of coffee and you’re walking back to your desk. The phone in your pocket begins vibrating as a flurry of emails show services are bouncing. The notifications say services were down but are now back up. You hustle back to your desk, spill a little coffee on your notepad, and open the VMware vSphere client to see a host in a disconnected state.
VMware Tanzu Application Service 2.13 unveils an improved Log Cache, which has been separated into its own virtual machine instance for enhanced scaling options. Historically, Log Cache has been colocated on Doppler virtual machine (VM) instances in order to reduce the footprint of foundations. This separation is critical as Log Cache is no longer subject to the formerly imposed Doppler maximum of 40 VM instances and can continue to scale up based on platform and application requirements.








