Software Development Life Cycle: Day 1 Best Practices
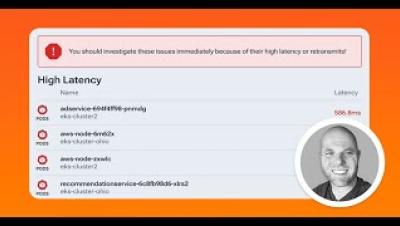
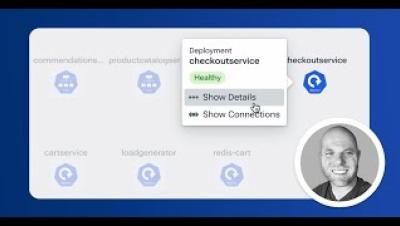
Welcome to Day 1 of the software development life cycle — what now? We’ve already covered Day 0 server provisioning, and you should be ready to start writing code that will support your DevOps initiatives and make your life easier …or are you? Put some of our wisdom and experience at work for Day 1 of the software life cycle, and make sure you’re fully prepared to handle common pitfalls and problems that can become ongoing issues for Day 2.