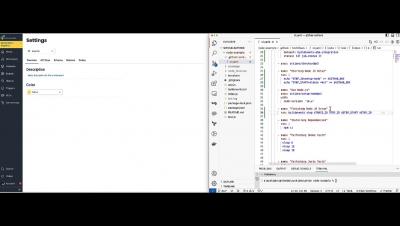
New related incidents functionality brings order to the chaos of highly complex incidents
We’ve all been there. You’re working through some rather frustrating blockers during an incident only to discover that you don’t own the dependency at fault. Or, you’ve been pounding away at an issue when a fellow engineer reaches out and asks if your service is affected by some particularly gnarly database failure they’re seeing. But then what? Do you merge efforts and work in parallel or head for a coffee break while the issue gets attacked upstream?