Pitfalls in Measuring SLOs Danyel Fisher & Liz Fong-Jones Failover Conf 2020
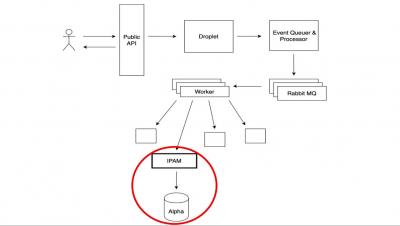
We built support for SLOs (Service Level Objectives) against our event store so we could monitor our own complex distributed system. In the process of doing so, we learned that there were a number of important aspects that we didn’t expect from carefully reading the SRE workbook. This talk is the story of the missing pieces, unexpected pitfalls, and how we solved those problems. We’d like to share what we learned and how we iterated on our SLO adventure.