

|
By Sarah Morgan
Last updated: July 2026. Your AI feature works in development. It demos well. Then it hits production and you discover three problems your test suite did not catch: the LLM hallucinates product names that do not exist, the RAG retrieval step adds 4 seconds to every request, and your OpenAI bill is 3x what you budgeted because one prompt template is burning tokens on context that does not help the output. Traditional APM would have caught the latency.

|
By Sarah Morgan
Your AI coding agent can refactor a module, write tests, and open a PR. It can read your codebase, understand your patterns, and suggest changes that follow your conventions. What it cannot do, unless you set it up, is see what is actually happening in production. That is a problem. The agent that writes the code should have access to the errors, traces, and performance data that code generates once it ships. Without production context, your agent is writing fixes based on the code alone.

|
By Sarah Morgan
Your Node.js app is slow and you are not sure where. The response time dashboard shows spikes but not causes. The logs say nothing useful. CPU looks fine. Memory looks fine. Users are complaining anyway. This is the standard Node.js performance debugging experience. The single-threaded event loop, async-everything execution model, and connection pool sharing across all requests make Node.js performance problems different from what you see in Ruby or Python.

|
By Sarah Morgan
Last updated: July 2026. Pricing verified against public vendor pricing pages on July 9, 2026. The monitoring tool market in 2026 is split. On one side, enterprise platforms keep adding features: security scanning, network monitoring, CI/CD integration, cost management. On the other, developer-focused tools are going deeper on what matters during a production incident: how fast you get from alert to the line of code that caused the problem.

|
By Sarah Morgan
Last updated: July 2026 Your Rails app throws a 500. You open Sentry and find the exception. The stack trace points to a controller action, but it does not tell you why the database call failed. You switch to Datadog and search for the request trace. The trace shows a 3-second query, but you do not know what the application was logging at that moment. You open your log aggregator, paste in the request ID, and scroll through output until you find the slow query log line that explains the lock contention.

|
By Aspen Clevenger
June was about finishing touches. The fun part. Node.js support, which we previewed in May, is live. Anomaly detection graduated with a rebuilt algorithm, per-monitor controls, and access from the API, CLI, and MCP server. We also kept pulling on the same thread from recent months: Scout data should be reachable from wherever you actually work. The MCP server now covers historical insights, anomaly events, and 30-day metrics. Discord is a notification channel. The CLI has scout anomalies.

|
By Aspen Clevenger
The Scout MCP server connects your AI assistant directly to your Scout Monitoring data. Instead of switching between your editor, Scout, and a chat window, your assistant can pull traces, errors, N+1 insights, and endpoint metrics on its own and use that context to suggest or make fixes right in your codebase. This covers how to connect it, what to ask it, how other teams are using it, and what we shipped recently.

|
By Aspen Clevenger
We have been getting the same request from teams for a while now: “We use Scout for our Rails app. Can we get the same thing for our Node services?” Today the answer is yes. Scout Monitoring now supports Node.js. If your team runs Express or NestJS in production, you get the same errors-and-traces experience that Ruby, Python, PHP, and Elixir teams have had. Let’s walk through what that means in practice.

|
By Sarah Morgan
You deploy on Friday. Sidekiq starts failing on a job that worked fine in staging. Your error tool shows you a NoMethodError on line 47. But it doesn’t tell you that the job only fails when processing records created after the migration you ran on Thursday. The stack trace is correct and completely useless at the same time. This is the core problem with general-purpose error monitoring on Rails apps. Rails teams deal with N+1 queries that cascade into timeout errors.

|
By Sarah Morgan
You don’t have an SRE. There’s no platform team. Your “monitoring strategy” is someone checking Slack for error alerts. When production breaks, the same two or three senior devs drop everything to debug. Sound familiar? Most APM tools are built for organizations with dedicated operations staff. They assume someone has time to configure dashboards, tune alert thresholds, and learn a complex query language. That person does not exist on your team.
|
By Scout
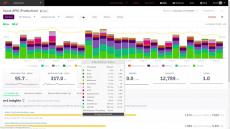
3 Key Benefits of switching to ScoutAPM over New Relic n+1 queries, Memory Bloat tabs show you easy performance enhancements.

- July 2026 (5)
- June 2026 (5)
- May 2026 (3)
- April 2026 (5)
- March 2026 (5)
- February 2026 (3)
- January 2026 (1)
- December 2025 (4)
- November 2025 (2)
- October 2025 (2)
- September 2025 (2)
- August 2025 (1)
- July 2025 (2)
- June 2025 (3)
- May 2025 (1)
- April 2025 (1)
- November 2024 (1)
- October 2024 (1)
- April 2024 (1)
- March 2024 (1)
- September 2023 (1)
- August 2023 (1)
- July 2023 (1)
- June 2023 (1)
- April 2023 (2)
- January 2023 (4)
- December 2022 (6)
- November 2022 (4)
- October 2022 (7)
- September 2022 (6)
- August 2022 (6)
- July 2022 (7)
- June 2022 (8)
- May 2022 (5)
- April 2022 (5)
- March 2022 (8)
- February 2022 (6)
- January 2022 (6)
- December 2021 (6)
- November 2021 (5)
- October 2021 (4)
- September 2021 (5)
- August 2021 (7)
- July 2021 (7)
- June 2021 (8)
- May 2021 (6)
- April 2021 (3)
- March 2021 (3)
- February 2021 (4)
- January 2021 (4)
- December 2020 (2)
- November 2020 (4)
- October 2020 (8)
- September 2020 (8)
- August 2020 (3)
- July 2020 (3)
- June 2020 (4)
- May 2020 (4)
- April 2020 (5)
- March 2020 (5)
- February 2020 (2)
- December 2019 (1)
- November 2019 (3)
- October 2019 (2)
- September 2019 (5)
- August 2019 (1)
- July 2019 (5)
- June 2019 (5)
- May 2019 (7)
- March 2019 (2)
- January 2019 (1)
- December 2018 (4)
- November 2018 (3)
- August 2018 (1)
- July 2018 (2)
- May 2018 (1)
- April 2018 (3)
- January 2018 (1)
- November 2017 (1)
Monitoring for the modern development team.
No developer ever said "I hope I get to spend all day hunting down a performance issue". When the unavoidable happens, The Scout platform is focused on finding the root cause of performance problems as quickly as possible.
Scout is monitoring for fast-moving dev teams like us. We leverage the tools that help us get big things done - Github, PaaS services, dynamic languages, frequent releases - to build a tailored monitoring platform for modern teams.
Scout continually tracks down N+1 database queries, sources of memory bloat, performance abnormalities, and more.
Get back to coding with Scout.