
GLM-5.2 Review (2026): Zhipu AI's Open-Weight Coding Model, Honestly Assessed
: Zhipu AI's Open-Weight Coding Model, Honestly Assessed")
Image Source: depositphotos.com
Zhipu AI (now operating internationally as Z.ai) shipped GLM-5.2 in mid-June 2026, and the claim that grabbed attention was blunt: an open-weight model that beats GPT-5.5 on several long-horizon coding benchmarks for roughly one-sixth of the cost. It's an MoE model with 753 billion total parameters released under an unrestricted MIT license, which means you can self-host it or call it through a managed endpoint. This GLM-5.2 review separates the verified specs from the vendor marketing — and if you'd rather test it against frontier models without juggling SDKs, you can run it today through OrcaRouter, which serves GLM-5.2 behind one OpenAI-compatible endpoint.
Quick take: GLM-5.2 is the strongest open-weight coding model of 2026 and a genuinely good value — independent ranking confirms it leads its open-weight class, and it undercuts GPT-5.5 on price by ~6×. But most headline benchmarks are Zhipu's own results, it trails the closed leaders slightly on some tests, and the 753B weights aren't trivial to self-host. Treat it as a strong, cost-efficient coding workhorse — and verify the scores that matter to you before betting a pipeline on them.
⚠️ Review status: GLM-5.2 launched on the GLM Coding Plan on 13 June and as a standalone API on 16 June 2026. Several benchmark figures below are Z.ai self-reported and not yet confirmed by a neutral harness. We flag verified vs. vendor claims throughout.
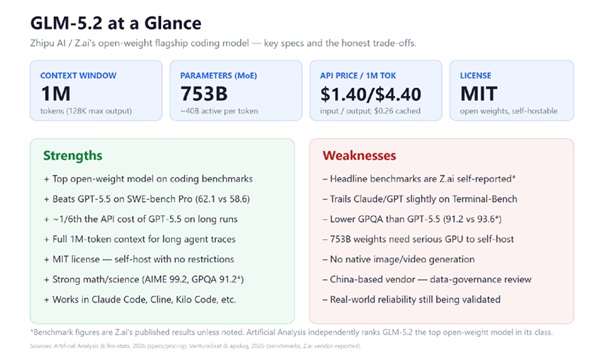
Key specs and honest trade-offs. Benchmark figures are Z.ai's published results unless noted. Source: Artificial Analysis, llm-stats; benchmarks via VentureBeat (Z.ai vendor-reported).
What is GLM-5.2?
GLM-5.2 is Zhipu AI's flagship open-weight model, purpose-built for long-horizon, agentic coding — multi-step work where an agent edits files, runs commands, reads output, and iterates over a long trajectory. It's a Mixture-of-Experts design with roughly 753B total parameters and about 40B active per token, which keeps inference cost down relative to a dense model of that size. The weights ship under a permissive MIT license on Hugging Face, so commercial use and self-hosting are unrestricted.
Context window and key specs
|
Spec |
GLM-5.2 |
|
Context window |
1,048,576 tokens (1M) |
|
Max output |
~128K tokens |
|
Architecture |
MoE, ~753B total / ~40B active |
|
License |
MIT (open weights) |
|
API price (input / output) |
$1.40 / $4.40 per 1M tokens |
|
Cached input |
$0.26 per 1M tokens |
|
Output speed |
~141 tokens/sec |
|
Released |
13–16 June 2026 |
The 1M-token window is the headline capability for agentic work — enough to hold a long, messy coding-agent trajectory (repo context, tool outputs, reasoning) without truncation.
Benchmarks: what's verified vs. claimed
This is where the GLM-5.2 review needs care: Zhipu's published numbers are impressive, but most are self-reported. The standout claim is SWE-bench Pro, where GLM-5.2 scores 62.1, edging out GPT-5.5's 58.6 on real-repo bug-fixing. On Terminal-Bench 2.1 it hits 81.0, trailing GPT-5.5 (84.0) and Claude Opus 4.8 (85.0) but well ahead of Gemini 3.1 Pro (74.0). Zhipu also reports AIME 2026 at 99.2 and GPQA Diamond at 91.2 — strong math, slightly behind GPT-5.5's reported GPQA (93.6). The key caveat: these are Z.ai's published results, and vendor benchmarks warrant independent verification.
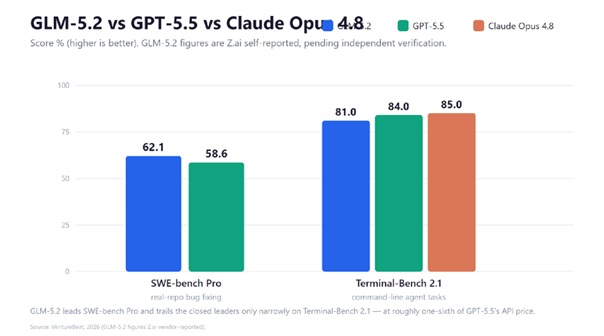
GLM-5.2 leads SWE-bench Pro and trails the closed leaders only narrowly on Terminal-Bench 2.1. Source: VentureBeat (GLM-5.2 figures Z.ai vendor-reported).
The one independently measured anchor: Artificial Analysis runs its own evaluations and ranks GLM-5.2 #1 among open-weight models in its size class on the Intelligence Index (51 vs. a median of 25). That doesn't put it ahead of the top closed models overall, but it substantiates the core narrative — GLM-5.2 is the open-weight model to beat.
Pricing and value
This is GLM-5.2's clearest win. The standalone API runs $1.40 / $4.40 per 1M input/output tokens, with cached input at $0.26. Against GPT-5.5's roughly $5 in / $30 out, that's the ~1/6th-the-cost framing — and for high-volume coding agents that burn output tokens, the gap compounds fast. If you'd rather not meter tokens, Zhipu's flat-rate GLM Coding Plan spans $18/mo (Lite) to $160/mo (Max) and works inside tools like Claude Code, Cline, and Kilo Code.
Strengths and weaknesses
Strengths
- ✅ Best open-weight model on coding benchmarks (independently #1 in its class)
- ✅ Beats GPT-5.5 on SWE-bench Pro (62.1 vs 58.6, vendor-reported)
- ✅ Roughly 6× cheaper than GPT-5.5 per API call
- ✅ Full 1M-token context and MIT license
Weaknesses
- ❌ Most headline benchmarks are Z.ai self-reported, pending neutral verification
- ❌ Trails Claude Opus 4.8 and GPT-5.5 on Terminal-Bench 2.1 and GPQA
- ❌ 753B weights demand serious GPU to self-host
- ❌ Text-only; China-based vendor warrants a data-governance review
Who should use GLM-5.2?
Great fit for teams running high-volume coding agents who want frontier-adjacent quality at a fraction of the cost, anyone who needs open weights for self-hosting or compliance, and developers in Claude Code or Cline who want a cheaper backend.
Look elsewhere if you need the absolute top score on every reasoning benchmark (GPT-5.5 and Claude Opus 4.8 still edge it on a few), can't run a 753B model and don't want a Chinese-vendor API in your data path, or need native image/video generation.
Is GLM-5.2 worth it?
For coding and agentic work, yes — with eyes open. GLM-5.2 delivers near-frontier coding performance, an independently confirmed #1 open-weight ranking, and pricing that undercuts the closed leaders by roughly 6×. The honest qualifier is that several of its most flattering numbers are Zhipu's own, and on a couple of benchmarks it sits just behind GPT-5.5 and Claude Opus 4.8. The responsible call: adopt it for cost-sensitive coding workloads, but benchmark it on your own tasks before migrating a production pipeline.
Frequently asked questions
Is GLM-5.2 better than GPT-5.5? On coding it's competitive — it beats GPT-5.5 on SWE-bench Pro (62.1 vs 58.6) but trails it slightly on Terminal-Bench 2.1 and GPQA. It's far cheaper, and those coding scores are Zhipu self-reported.
How much does GLM-5.2 cost? $1.40 / $4.40 per 1M input/output tokens via API, or a flat GLM Coding Plan from $18/mo.
What is GLM-5.2's context window? 1M tokens (1,048,576), with up to ~128K output.
Is GLM-5.2 open source? Yes — the weights are released under an MIT license, allowing commercial use and self-hosting.
Are the benchmarks independently verified? Mostly not yet. The coding and reasoning scores are Z.ai's published results; the one independent anchor is Artificial Analysis ranking it #1 open-weight model in its class.