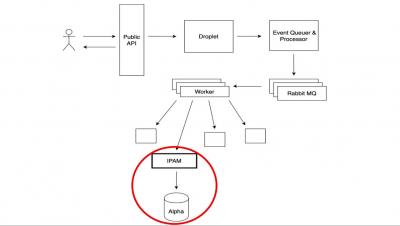
How many 9's are enough? Kolton Andrus CTO Connection: Reducing engineering cycle time
How many nines of availability are enough? In this talk, Gremlin CEO Kolton Andrus shares insights from years at Amazon, Netflix, and now working with a wide array of customers across various disciplines and industries. He’ll describe what each level of availability looks like, the challenges faced at each stage, and the trade-offs required to achieve the next nine of uptime.