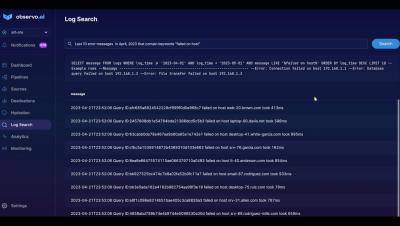
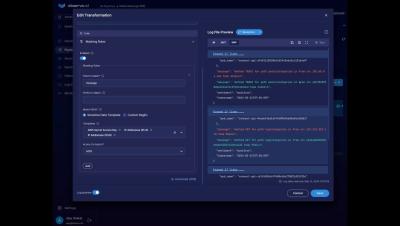
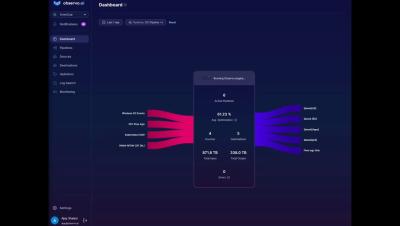
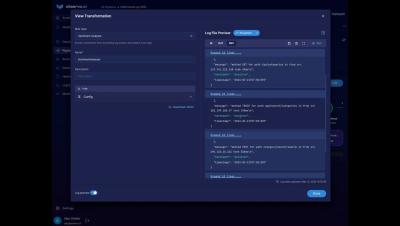
In this demo first shown at Splunk.conf24, we look at the data-lake creation feature of Observo. Data is stored in the parquet format - a open columnar format. We also support searching the data-lake based on natural language search - under the hood this functionality uses LLM for text to SQL functionality. Use the rehydrate function to send any subset of data to the analytics platform of choice, on-demand. Consider keeping a smaller Splunk index, and use the lake for retention - retain more data, longer, for a lot less cost, all in a flexible format.