

|
By Prathamesh Sonpatki
Monitoring your infrastructure shouldn’t be a shot in the dark. The Prometheus API helps you pull the right metrics so you actually know what’s going on. Whether you’re just getting started or trying to make sense of your current setup, this guide breaks down how to use the API to get the answers you need—without the guesswork.

|
By Aditya Godbole
So, you're wrestling with Nginx logs, huh? Been there. In fact, I used to spend way too much time hunting down log files until I finally got smart about it. Let me save you the trouble. Nginx logs are like the black box flight recorder for your web server. When everything crashes and burns (and it will), those logs are often the only evidence left to figure out what happened. But first, you need to know where to find them.

|
By Preeti Dewani
If you’ve ever needed to check how much CPU or memory a Docker container is using, docker stats is the command for the job. It provides real-time resource usage metrics, helping you monitor and troubleshoot containers efficiently. This guide covers everything you need to know about docker stats: how to use it, what each metric means, and how to integrate it into a larger monitoring setup.

|
By Anjali Udasi
That moment when your production system goes down, and you're stuck piecing together logs from twenty different services? It’s frustrating and slow—especially when you need answers fast. SIEM logs help bring order to this chaos, giving you a structured way to track security events and system activity. But understanding how to use them effectively isn’t always straightforward, and most documentation can feel more complicated than the problem itself.

|
By Prathamesh Sonpatki
Building dashboards one by one in Grafana can quickly become tedious. Clicking through the UI for every change isn’t exactly efficient. There’s a better way. The Grafana API lets you automate repetitive tasks and extend Grafana’s capabilities beyond the UI. If you're new to monitoring or managing a complex observability setup, understanding the API can make your workflow more efficient and scalable.

|
By Preeti Dewani
Debugging a Python app can be frustrating, especially when an unexpected crash leaves behind nothing but a vague error message. A well-configured exception log can make all the difference, turning guesswork into clear insights. Here’s how to set up logging that actually helps.

|
By Anjali Udasi
Monitoring your EC2 instances shouldn’t be complicated or exhausting. Yet, too often, engineers find themselves troubleshooting issues in the middle of the night, searching for the root cause of an unexpected failure. Whether you're managing a few instances or hundreds spread across multiple regions, effective EC2 monitoring helps you stay ahead of problems instead of constantly reacting to them. And if you've ever dealt with a critical alert at an inconvenient hour, you know how important that is.

|
By Preeti Dewani
Nginx error logs can be tough to decipher, even for experienced sysadmins and DevOps engineers. They hold valuable clues about what’s going wrong, but sorting through them can feel overwhelming. Understanding these logs doesn’t have to be a challenge. This guide breaks them down in a clear, practical way—so you can find the issues that matter and fix them with confidence.

|
By Ujjwal Goyal
When your Linux server starts acting up at 3 AM, you don't need a philosophy lesson—you need answers. Fast. That's where journalctl last comes in, the command-line equivalent of having a time machine for your system's events. If you've been piecing together log information like some digital detective with a cork board and string, it's time to upgrade your toolkit. Let's cut through the noise and get you the intel you need, when you need it.

|
By Anjali Udasi
Choosing between OpenTelemetry and Datadog isn't just another tool decision. It's about how you'll monitor your systems, troubleshoot issues, and ultimately keep your services running smoothly. If you've been tasked with figuring out which route to take, you're in the right place. Let's get started!

|
By Last9
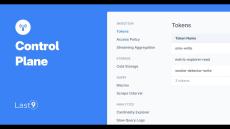
Levitate is a high-cardinality monitoring tool and a telemetry data warehouse with support for metrics, events, logs, and traces. Prometheus and OpenTelemetry compatibility makes it easy to get started with a hassle-free monitoring journey, be it starting from scratch or even swapping out your existing monitoring tool. Used by engineering teams worldwide at companies like Replit, Disney+ Hotsar, Clevertap, Probo, Quickwork, Axio, and more.
|
By Last9
The most apt alert rules toolkit for your Prometheus setup. Connect your Prometheus setup. Discover components emitting metrics. Get recommendations of rules to be applied.

|
By Last9
Last9 Levitate’s integration with LaunchDarkly enables change intelligence with feature flag events. Visualize the feature flag events as Change Event annotations in Levitate to correlate system health.

|
By Last9
Last9 Levitate’s integration with LaunchDarkly enables change intelligence with feature flag events. Visualize the feature flag events as Change Event annotations in Levitate to correlate system health.


|
By Last9
Using template variables to insert dynamic values based on labels for use cases like detailed alert descriptions, routing links, etc.
|
By Last9
Are you using Prodvana.io for deployments? Send a change event to Levitate for every deployment from Prodvana.

|
By Last9
You have probably heard of OpenTelemetry in the context of traces. But did you know OpenTelemetry also supports metrics with a comprehensive, forward-looking data model and SDKs? When it comes to metrics, one thinks of Prometheus, but Otel metrics provide exciting ideas such as cumulative deltas, exponential histograms, and more! This talk will demystify everything about Otel Metrics, from the data model to APIs to how to get started. We will cover the differences between Otel Metrics and Prometheus and explain the reasons why people get excited about using Otel Metrics.

|
By Last9
The Indian Premier League is a unique sporting event for a dozen reasons. But for engineers in India, it’s one of a kind. Very few companies can boast of managing 30+ million concurrent users. Every year, this number grows. Last year, we witnessed ~60 million concurrent users. And things get bigger and larger every year.
- March 2025 (9)
- February 2025 (46)
- January 2025 (58)
- December 2024 (38)
- November 2024 (26)
- October 2024 (17)
- September 2024 (24)
- August 2024 (11)
- July 2024 (4)
- June 2024 (9)
- May 2024 (2)
- April 2024 (2)
- March 2024 (3)
- February 2024 (2)
- January 2024 (4)
- December 2023 (5)
- November 2023 (11)
- October 2023 (24)
- September 2023 (5)
- August 2023 (8)
- July 2023 (13)
- June 2023 (10)
- May 2023 (11)
- April 2023 (3)
- March 2023 (4)
- February 2023 (1)
- January 2023 (2)
- December 2022 (1)
- November 2022 (1)
- February 2022 (1)
Last9 provides tools to improve Reliability in large-scale cloud-native environments.
Our open-standards-based tools provide visibility into the Rube Goldberg of micro-services. We take away the toil of managing a time series database by dramatically reducing your costs and improving developer productivity.
Levitate is our time series metrics & events warehouse designed for scale and high cardinality. Our warehousing capabilities provide necessary control levers to ensure cost-efficient data growth management, surpassing traditional storage solutions.
Start your observability journey today with Levitate. A Managed Time Series Data Warehouse that SREs trust.