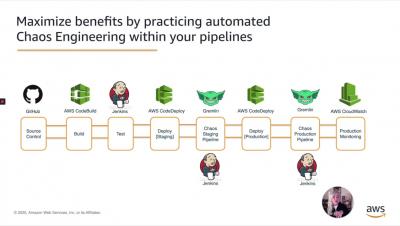
Grubhub and JPMC Shift Reliability Testing Left at Chaos Conf 2020
Get started with Gremlin's Chaos Engineering tools to safely, securely, and simply inject failure into your systems to find weaknesses before they cause customer-facing issues. Gremlin’s Chaos Conf is always an exciting event, bringing together leaders at the forefront of Chaos Engineering practices. This year was no exception, moving beyond defining Chaos Engineering to more advanced adoption and best practices discussions.