New Product Updates What Does it Mean to Observe and Debug in 'Hi Res'
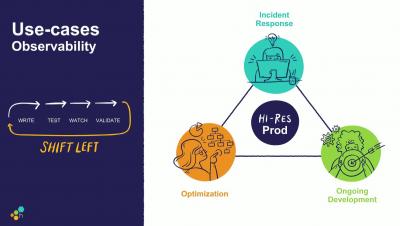
A number of Honeycomb features have been released throughout spring 2019 that, collectively, we like to say deliver “hi-res” across the Engineering and DevOps lifecycle. What do we mean? First, hi-res with Honeycomb means you get clearer visibility about how your production is behaving in real time, as you release new code. Secondly, it means once you have those insights (thanks to granular event data stored in Honeycomb), you can debug and resolve more efficiently. So, how do we do it?