
Enhancing Aspire with AI: integrating Ollama for local error resolution

In this article, we’ll explore how we developed an Aspire component that spins up an Ollama container and downloads a Large Language Model, ready for use. If you’re new to any of these technologies, you can continue reading, otherwise feel free to skip to the technical walkthrough.
As a quick bit of background, we recently released an Aspire component that brings a free, lightweight Raygun app into your local development environment to help debug exceptions. We then subsequently enhanced this with AI Error Resolution capabilities which runs entirely on your local machine.
Technologies we’ve used
Develop cloud-native apps with Aspire
Aspire is a comprehensive framework designed to simplify the development experience of creating cloud-native applications. At the center of an Aspire project is the orchestrator app which uses Docker behind the scenes to spin up all the resources needed for your application to function. These resources can be anything from databases to web APIs and even resources that just aid in local development.
LLMs power today’s AI systems
Artificial Intelligence in this day and age is achieved using Large Language Models (LLMs). These typically utilize a neural network architecture known as the Transformer, which has proven to be highly effective for natural language processing tasks. Transformers are trained on extensive datasets containing text from books, articles, websites, and other textual sources—including how to fix software exceptions. Among other components, Transforms contain word embeddings made up of dense vectors that represent the semantic meaning of words.
Use Ollama to run AI on your local machine
To get AI Error Resolution working locally, we needed a small but powerful open-source Large Language Model (LLM) that could run efficiently in a Docker container. After exploring various options, we opted for Meta’s Llama models due to their efficiency and quality. Running these models locally can be done with Ollama which offers a server application that we can interact with through web requests. There is also already an Ollama Docker image available which is perfect for what we needed and saves us from building our own one.
How we built the Ollama Aspire component
1. Initial creation of the resource and extension method
Let’s start by creating the basic foundations of an Aspire component. We found out how to do this from the Aspire documentation, and by looking at the source code of built-in Aspire components. First, we create a model class that extends ContainerResource, because this component is going to spin up a Docker container.
namespace Aspire.Hosting.ApplicationModel
{
public class OllamaResource : ContainerResource
{
}
}Then, we create the AddOllama extension method as seen below. The key piece here is the ContainerImageAnnotation, which states the Docker image to fetch.
namespace Aspire.Hosting.ApplicationModel
{
public static class OllamaResourceBuilderExtensions
{
public static IResourceBuilder<OllamaResource> AddOllama(this IDistributedApplicationBuilder builder,
string name = "Ollama", int? port = null)
{
var raygun = new OllamaResource(name);
return builder.AddResource(raygun)
.WithAnnotation(new ContainerImageAnnotation { Image = "ollama/ollama", Tag = "latest" })
.WithHttpEndpoint(port, 11434)
.PublishAsContainer();
}
}
}The little bit of code above so far allows us to add this Ollama component to an Aspire orchestrator project (AppHost) using the line below.
var ollama = builder.AddOllama();When running the Aspire project, “Ollama” will be listed in the resource table and will be running the Ollama Docker container as specified. If we click on the endpoint link, we get back the response: “Ollama is running“.
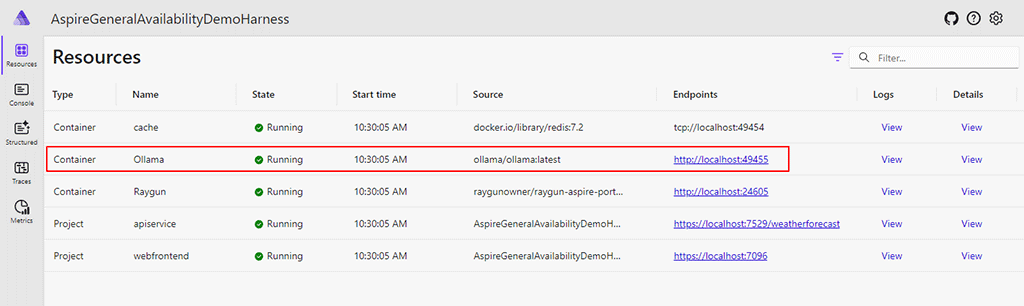
2. Adding an endpoint to the resource
We want other components to be able to reference this Ollama component and access its endpoint. To do this, we need to add a ReferenceExpression to the OllamaResource, again by following the guide in the Aspire documentation.
Back in the OllamaResource class, we need it to implement the IResourceWithConnectionString interface. We add the EndpointReference and ReferenceExpression as seen below. The expression allows the endpoint string to be built when all the information is available. Aspire dishes out a random port to the resource each time the app starts up. To my understanding that port may not be known until later after the OllamaResource model has been constructed.
public class OllamaResource : ContainerResource, IResourceWithConnectionString
{
internal const string OllamaEndpointName = "ollama";
private EndpointReference? _endpointReference;
public EndpointReference Endpoint =>
_endpointReference ??= new EndpointReference(this, OllamaEndpointName);
public ReferenceExpression ConnectionStringExpression =>
ReferenceExpression.Create(
$"http://{Endpoint.Property(EndpointProperty.Host)}:{Endpoint.Property(EndpointProperty.Port)}"
);
}Back in the extension method, it’s important that the http endpoint we configure uses the same name as the endpoint reference in the Ollama resource above.
.WithHttpEndpoint(port, 11434, OllamaResource.OllamaEndpointName)Within the Aspire orchestrator project we can now reference the Ollama component into other components.
builder.AddRaygun().WithReference(ollama);Running the Aspire orchestrator app shows that such components now list a connection string to Ollama. To see this for yourself, click the “View” link in the “Details” column of a component that references Ollama. Then scroll to the bottom of the details panel that opens to find the connection string in the “Environment variables” section.
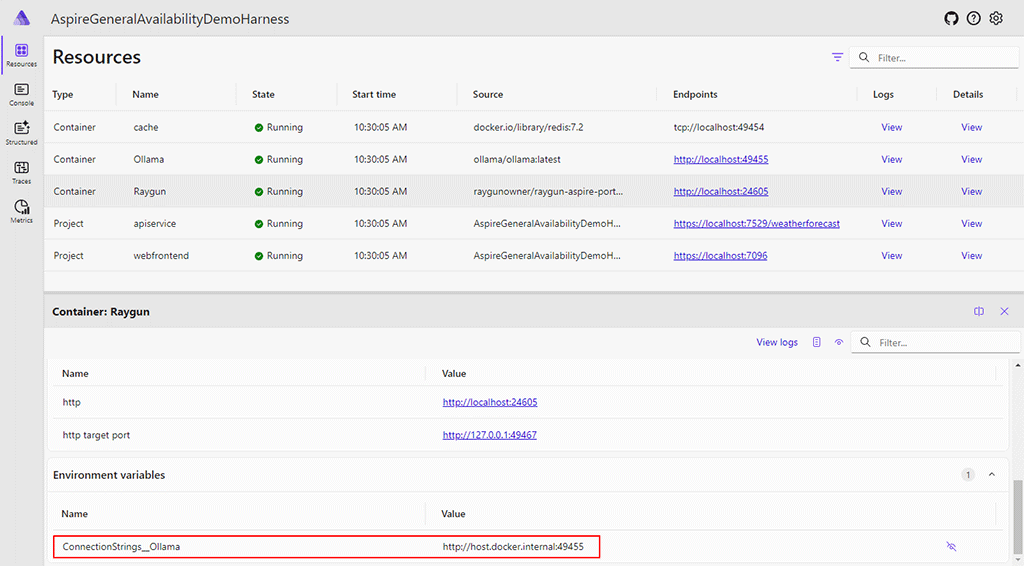
In the code of another component, you can fetch and use this connection string with the following line:
var connectionString = builder.Configuration.GetConnectionString("Ollama");3. Add a volume to persist the model
With the basics laid down, we now want this Ollama component to be able to download a Large Language Model when it first starts up. This can take a while to download, so we also want to make sure that this model is persisted to the local machine to avoid downloading it again every time. This is easy to achieve by configuring a Volume in the resource extension method from earlier. In the below line of code, “ollama” will be the name of the volume as it appears in the Docker desktop app. Whereas “/root/.ollama” is the path within the Ollama Docker container where we know Ollama keeps its downloaded models.
.WithVolume("ollama", "/root/.ollama")4. Adding a lifecycle hook to download a model
Now let’s examine the code that performs the model download and displays the progress of the download within the Aspire orchestrator dashboard. This is achieved by implementing a lifecycle hook. The code below shows how we get started building such a class, which so far has two main bits. Firstly, we inject a ResourceNotificationService. This is what allows us to customize what gets displayed in the “State” column for our resource in the resource table. Secondly, we implement the AfterResourcesCreatedAsync method. The lifecycle hook service itself is a singleton. Just in case there are multiple Ollama resources, we fetch all of them and manage downloading their respective models individually which I’ll explain further below.
internal class OllamaResourceLifecycleHook : IDistributedApplicationLifecycleHook
{
private readonly ResourceNotificationService _notificationService;
public OllamaResourceLifecycleHook(ResourceNotificationService notificationService)
{
_notificationService = notificationService;
}
public Task AfterResourcesCreatedAsync(DistributedApplicationModel appModel, CancellationToken cancellationToken = default)
{
foreach (var resource in appModel.Resources.OfType<OllamaResource>())
{
DownloadModel(resource, cancellationToken);
}
return Task.CompletedTask;
}
}We haven’t included it in the code examples in this blog post, but We’d also added a “ModelName” property to the OllamaResource to state which model should be downloaded on startup by default. In the DownloadModel method, we first want to check whether or not the container for the given resource already has the specified model. We can do this by querying the /api/tags endpoint of the Ollama server running on the container.
To get the connection string to query Ollama, you’ll see below that we evaluate the ConnectionStringExpression that we added to the resource earlier. With that, we are then using OllamaSharp to check what models the container has available. In the code below there are also examples of using the resource notification service to modify the “State”. Here we’re simply providing some text to be displayed, and a state style that will affect which icon to be displayed.
private void DownloadModel(OllamaResource resource, CancellationToken cancellationToken)
{
if (string.IsNullOrWhiteSpace(resource.ModelName))
{
return;
}
_ = Task.Run(async () =>
{
try
{
var connectionString = await resource.ConnectionStringExpression.GetValueAsync(cancellationToken);
var ollamaClient = new OllamaApiClient(new Uri(connectionString));
var model = resource.ModelName;
var hasModel = await HasModelAsync(ollamaClient, model, cancellationToken);
if (!hasModel)
{
await PullModel(resource, ollamaClient, model, cancellationToken);
}
await _notificationService.PublishUpdateAsync(resource, state => state with { State = new ResourceStateSnapshot("Running", KnownResourceStateStyles.Success) });
}
catch (Exception ex)
{
await _notificationService.PublishUpdateAsync(resource, state => state with { State = new ResourceStateSnapshot(ex.Message, KnownResourceStateStyles.Error) });
}
}, cancellationToken);
}
private async Task<bool> HasModelAsync(OllamaApiClient ollamaClient, string model, CancellationToken cancellationToken)
{
var localModels = await ollamaClient.ListLocalModels(cancellationToken);
return localModels.Any(m => m.Name.StartsWith(model));
}If the desired model is not found in the Ollama container, we use OllamaSharp again to request that said model be pulled. This streams back many response payloads, most of which have a “Completed” and “Total” number that we can use to calculate the percentage of progress. We then announce this percentage to the “State” column via the notification service. We found that punctuation gets stripped away, maybe because of the use of Humanizer in the Aspire code, so we had to resort to displaying integer values and the word “percent” instead of a symbol.
private async Task PullModel(OllamaResource resource, OllamaApiClient ollamaClient, string model, CancellationToken cancellationToken)
{
await _notificationService.PublishUpdateAsync(resource, state => state with { State = new ResourceStateSnapshot("Downloading model", KnownResourceStateStyles.Info) });
long percentage = 0;
await ollamaClient.PullModel(model, async status =>
{
if (status.Total != 0)
{
var newPercentage = (long)(status.Completed / (double)status.Total * 100);
if (newPercentage != percentage)
{
percentage = newPercentage;
var percentageState = percentage == 0 ? "Downloading model" : $"Downloading model {percentage} percent";
await _notificationService.PublishUpdateAsync(resource,
state => state with
{
State = new ResourceStateSnapshot(percentageState, KnownResourceStateStyles.Info)
});
}
}
}, cancellationToken);
}Last of all, we just need to register the lifecycle hook to the services collection. We do this in the AddOllama extension method with the following line of code.
builder.Services.TryAddLifecycleHook<OllamaResourceLifecycleHook>();Now, when the Ollama Aspire resource spins up, it’ll download the specified model on its first startup. The progress of the model download is displayed in the “State” column which is an essential quality of life feature.
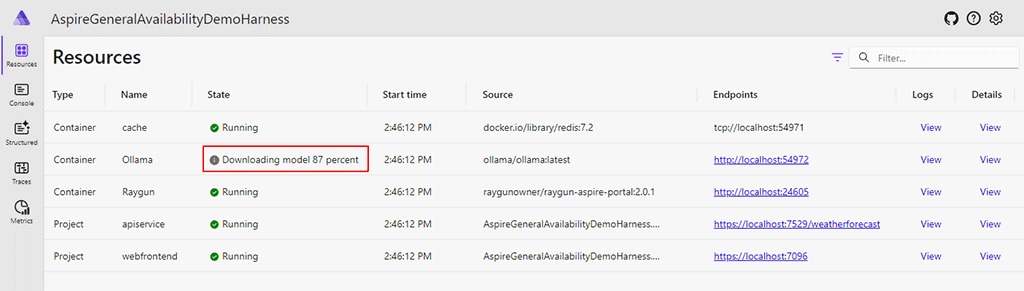
Although we built this Ollama Aspire component because we needed it for Raygun AI Error Resolution, we implemented it in a way that anyone who needs AI capabilities in a local Aspire project can use it. The source code demonstrated in this article can be found up on GitHub, and you can integrate the component into your project via NuGet.
Integrating AI-driven error resolution into your local development environment can drastically improve your debugging process. With our free to use Raygun4Aspire Crash Reporting client, you can leverage the power of Meta’s Llama models and Ollama’s seamless integration to catch and fix exceptions faster than ever before. You can check out our documentation to get started.
Not a Raygun customer yet? Try out the full Crash Reporting application free for 14 days! No credit card required.