
Traffic-Driven Testing: All the Benefits of Shift-Right Testing with None of the Risk

The shift-right testing approach moves testing to later in your production cycle. Also known as “testing in production,” with shift-right, you test software after it has been deployed. It gives you continuous feedback based on real-world user interactions. However, there are major drawbacks to the approach.
For example, testing in production risks disrupting your user satisfaction and can mean you catch issues too late to respond to them effectively. It can also be difficult to test problems related to scale and traffic volume. Your tests are also difficult to repeat under the same conditions.
Traffic-driven testing is an increasingly popular alternative that improves on the shift-right approach in several ways. With it, you capture user traffic and use it in your tests. However, unlike with shift-right, you can replay it repeatedly and in any environment.
In this article, you’ll learn more about traffic-driven testing and how you can use it to avoid the pitfalls of shift-right testing while retaining the benefits. You’ll also be introduced to Speedscale and how it can help you implement the traffic-driven approach to get more from your tests.
Why Use Shift-Right Testing?
Shift-right testing practices arose from the need to get tests that better reflect how users interact with a product and from faster deployments that leave less room for robust testing earlier in the development lifecycle.
It uses a number of common methods, including feature flags, canary releases, blue-green deployments, and A/B testing.
If your team has a SaaS product, you typically want to introduce new features quickly, practicing continuous deployment. However, in a microservices-based architecture, changes will lead to your production environment becoming out of sync with your test scripts. This, in turn, requires you to spend significant time rewriting the tests to avoid them failing because they simply don’t reflect the current state of your architecture.
It’s here that shift-right testing comes to the fore. When combined with other tests, it allows you to constantly update your software and check that it performs adequately in real-world conditions, and it can identify problems that your earlier tests have missed.
When testing in production, you gain valuable insights into how users interact with the software application and test against the range of unpredictable behaviors that result. It can catch bugs, identify problems with performance, and allow you to make improvements based on feedback.
Problems with Shift-Right
Though shift-right testing practices have advantages, there are several risks associated with them. For example, if you shift your focus too far toward production testing, you risk presenting users with a less mature product. It has the potential to disrupt your customers’ experience, as issues are not caught before reaching production.
When issues are found, they are already in production, meaning you have to be reactive and deal with them immediately. Some defects you find in production could have a cluster-wide effect, such as issues that cause CPU spikes.
There are also problems with testing at scale. Some issues might not show themselves under low call volumes but only emerge as traffic ramps up. When you’re dependent on real-world traffic, it’s hard to target these kinds of issues. Since conditions change all the time, anything involving load balancing or traffic volume is difficult to test systematically under the shift-right approach.
It’s important to get the balance right in your software testing cycle and make sure you cover all bases. Testing before deploying to production allows for early bug detection before they affect customers. Later tests use real-world data but highlight problems too late to deal with them. That’s where traffic-driven testing comes in.
What is Traffic-Driven Testing?
Traffic-driven testing uses real traffic for testing but doesn’t restrict you to running tests in production. You capture the traffic and reuse it later.
Like shift-right, traffic-driven testing uses real user data to power your tests, but you can manipulate and control this data. It’s especially useful for capturing the complex data flows between microservices. As you’ll see, that provides several advantages while eliminating or mitigating issues with shift-right.
Essentially, you capture the traffic you would usually test with under shift-right, which you can then use repeatedly and systematically. You can change it if needed, as well as vary the volume or speed of requests. You can also vary your code or infrastructure and test it with the same set or sets of traffic.
That way, you can hone in on exactly what is causing issues and get metrics that show the impact of changes. In a complex, microservices-driven architecture, you need to be able to see the impact of changes as calls work their way around your system and hunt down potential errors among the many steps that a single REST call can trigger.
With this approach, you get the same benefits as with shift-right testing. You’re using user traffic, which changes with real-world conditions and reflects how users interact with your current deployment. Your data reflects issues and outages accurately.
Check out our tutorial on Traffic Driven Testing in Kubernetes
How Traffic-Driven Testing Gives You the Benefits of Shift-Right without the Risk
With traffic-driven testing, the drawbacks of shift-right testing have been eliminated. Your test strategy no longer risks disrupting the user’s experience. Traffic-driven testing provides more test coverage, allowing you to test under different conditions, and identify issues before they appear in production.
The capacity to vary the conditions your tests run under eliminates further issues with shift-right testing. You can spot issues that would otherwise only show themselves by impacting end users. For example, if your setup can’t cope with a certain request volume, you won’t spot that with shift-right testing until it occurs.
With traffic-driven testing, you can simulate higher call volumes. You do that by simply repeating the calls you capture or by running them faster. You can increase the call volume until your system shows its limits. Speedscale lets you multiply the volume of your captured traffic or increase and decrease it as required.
Of course, traffic-driven testing doesn’t limit you to using real user traffic. For example, with Speedscale, you can create custom traffic when needed and modify request details. You can adjust URLs or headers. Speedscale also lets you modify traffic using its GenAI data generation, by creating new traffic that resembles your real data. It can automatically create mocks. In addition, you can use its metrics to spot any variations between traffic sources or test sources.
With traffic-driven testing, you can change your code and test it with repeatable conditions. That lets you quantify the effect of specific changes and verify what works.
How Speedscale Helps Deliver Traffic-Driven Testing
Now that you’ve learned about the benefits of traffic-driven testing, let’s shift your focus to making it happen. It might sound challenging to implement. If setting it up yourself, you would need to capture the traffic, store it, build the infrastructure to repeatedly make calls with it, and then log and quantify the results.
Speedscale is designed to address these needs and allow users to set up traffic-driven testing quickly and easily. You can use it through its web UI or from the command line. Once you’ve got the data, you can use it to simulate a real user session that you can test against other environments or with different traffic levels.
Speedscale uses a complex rules engine to automatically create test scenarios for you based on its analysis of your traffic. It can automatically generate mocks for you and identify the backends you need to use. It can also generate new traffic permutations based on your real data.
Speedscale also automatically removes personally identifiable information (PII). That solves a problem with storing this data, which would otherwise risk violating regulations on customer data use.
Getting Started with Speedscale
The Speedscale workflow is based around observing traffic, analyzing it, and then replaying it. To enable this, you need to set it up to capture your traffic.
First, you need to get an API key and install Speedscale’s CLI. There are further steps, depending on where you want to run the app from.
Then, the quickest way to see how it works is to download one of the demo apps. There are various demo apps on GitHub. There’s one for Node, one for Kubernetes, and a Java Spring Boot app.
You then need to capture traffic in a live environment. If you’re using Kubernetes, you can install its operator on your cluster and run it with the following command:
```javascript
make kube-capture
```Once Speedscale is running, you can start capturing live traffic, which you can view on the Speedscale dashboard. You can replay the traffic in your tests and see how your system responds under various conditions. Traffic can be replayed by Speedscale’s web UI or from the CLI.
Speedscale’s web UI includes a traffic viewer where you can check the data going to and from your services:
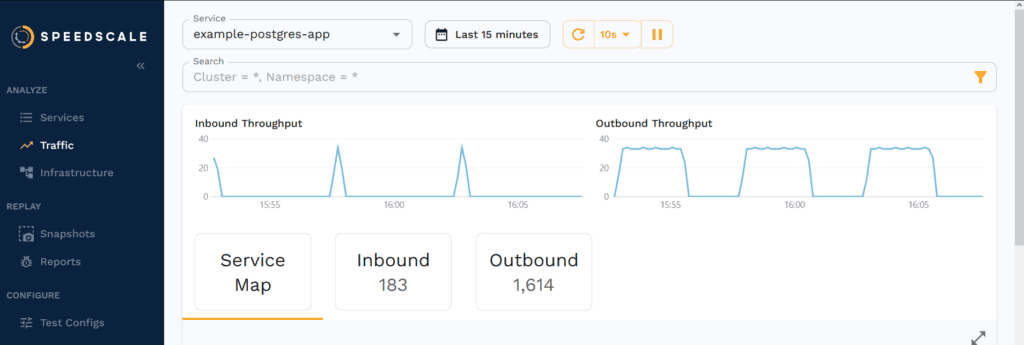
You can save snapshots of this traffic for use in testing. On the snapshot screen, you can view the various snapshots you’ve taken. Here’s an example snapshot of a payment being made:
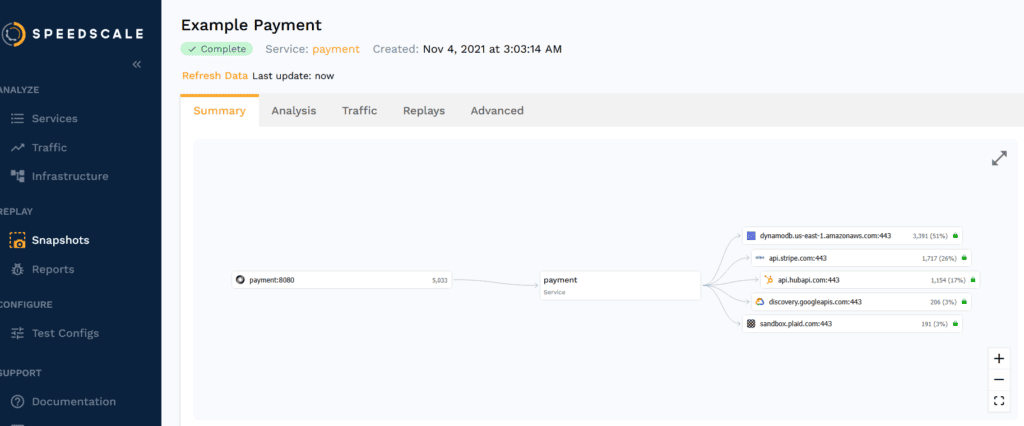
On this summary diagram, you can see the call being made, the service it connects to, and the various endpoints that the service then uses. On further tabs, you can view the latency for each endpoint and the traffic for each one. You can also check the contents of incoming request payloads (and those sent to related services) in detail.
You can tune test configurations in Speedscale too. You can run tests, mocks, or both on the data and adjust various parameters, as seen below:
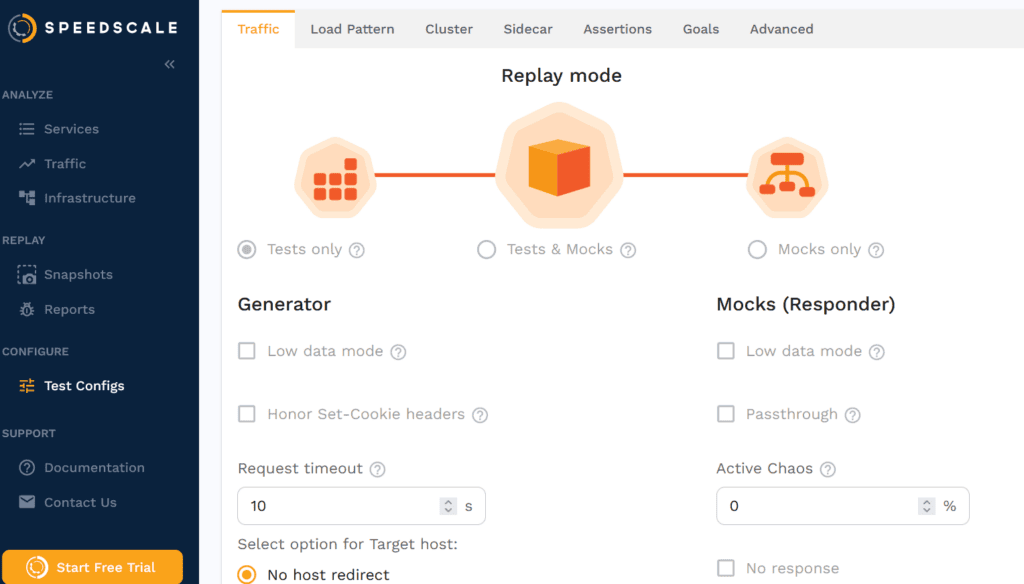
You can vary load patterns and change the volume of logging recorded. You can also set goals, or configurable threshold conditions, and then receive alerts when those conditions are met. You can also use assertions to validate responses from your service. These can be applied to specific subsets of traffic, letting you set different conditions for each.
From here, you can gain valuable insights from analyzing the data and use it to identify problems. You can then make improvements accordingly by fixing bugs, tuning services to handle traffic spikes, or solving whatever problems your quality assurance testing indicates.
You can then test again using the same traffic simulation to directly compare how your services respond to it. It’s a continuous testing process where your findings can drive further improvements.
Article from our co-founder, Nate Lee, on why your testing doesn’t work.
Conclusion
Getting your testing strategies right directly impacts how quickly you can improve your product. Switching from shift-right to traffic-driven testing offers many benefits, such as seeing how real user data affects your product and how users interact with it.
But you can do better. Traffic-driven testing gives you the accuracy of real-world data while letting you experiment with and repeat testing scenarios. You can do all this without impacting the user experience, and the insights you gain will improve your app faster.
Speedscale lets you implement traffic-driven testing quickly and easily by giving you all the necessary testing tools in one place. Take a look at its demo and get a free trial to learn how it can help you get better results from your tests.