Sensu Success Story: Netsmart Technologies
Sensu enterprise customer Christopher Sabo shares the details of his Sensu implementation with Puppet, Docker and more at Netsmart Technologies.


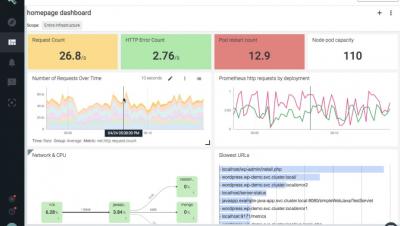
Brendan Gregg’s USE (Utilization, Saturation, Errors) method for monitoring is quite known. There are even some monitoring dashboard templates shared on the Internet. There’s also Tom Wilkie’s RED (Rate, Errors, Durations) method, which is suggested to be better suited to monitor microservices than USE. We, at okmeter.io, recently updated our PgBouncer monitoring plugin and while doing that we’ve tried to comb everything and we used USE and RED as frameworks to do so.
Your private network is teeming with web services (APIs), intranet, business applications like CRMs and ERPs, acceptance and preproduction environments, databases, and other servers. Your business relies on your network infrastructure to function every day. Each part of that infrastructure needs to be available, performing, and functioning well to keep your business humming along.
In an ideal world, your DevOps toolchain would be highly automated for incident management and allow your teams to resolve issues at DevOps speed. An alert triggered by monitoring tools like Datadog or AWS Cloudwatch would notify on-call engineers, kick your collaboration tools into gear (ChatOps, StatusPage, etc), and automatically document the issue in ITSM and ticketing tools.
Anyone trying to access resources in your network needs to interact with your network devices: firewalls, routers, switches, and IDS/IPSs. Each of these devices generate syslogs that contain important security information and must be audited to gain complete visibility into the activities occurring in your network. Most SIEM solutions, including our own Log360, can collect and analyze syslogs in real time and instantly alert security teams if any security event of interest occurs.