Operations | Monitoring | ITSM | DevOps | Cloud




Reliability Through Automation for Your Infrastructure and Applications at Scale

What Your System Outage Notifications Need To Say
System outages happen to the best of us. Communicating with your customers and other stakeholders effectively during downtimes is vital to maintaining a solid relationship with them. When a system outage occurs, technical teams are tasked with swiftly locating the cause and resolving the issue, while communications teams are tasked with notifying stakeholders and customers about the outage to maintain transparency.


What is Incident Response?
When a service is down, a system is failing, or a security issue is in the midst of occurring, organizations need a solid incident response process to get up and running again. Incident response isn't just for high severity, lights out incidents either; if you've rebooted your computer to fix a problem, you've been an incident responder yourself! Incidents happen, and any successful organization knows that instead of pretending that one day nothing will ever go wrong, it's far more useful to develop a comprehensive operational response plan. And to do so, you need to know what incident response is! Let's get into it.




What is a Workflow?
Workflows are no stranger in the DevOps world. But where did this term come from, and what does it really mean? Perhaps it’s no surprise that workflows originated from the industrial revolution, which brought powerful machinery for mobilizing huge workforces unlike ever before. To maximize the potential of these new industrial tools, people had to first figure out the best way to use them to get work done as efficiently as possible.

xMatters Ninja Release Updates - xMatters Demo
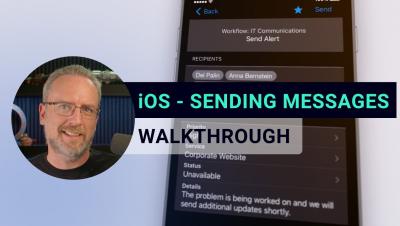
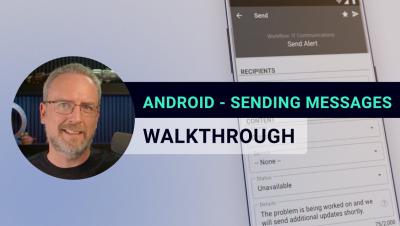

What the Ideal Incident Lifecycle Should Be
Today’s organizations are managing increasingly complex IT ecosystems and pressured to deliver on innovation—all while trying to maintain service performance and reliability to keep up with the always-on digital economy. With IT complexity growing exponentially, incidents have become a common, if not day-to-day struggle for many businesses. Incident management is the process or method that modern organizations use to prepare for and respond to service disruptions.
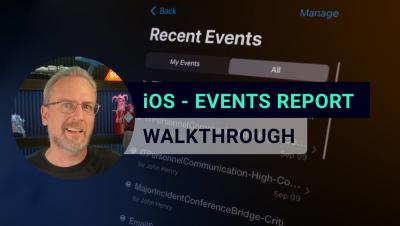


7 Incident Management Best Practices for Long Term Success
Incidents can have a massive impact on your operations, negatively affecting customers, employees, and stakeholders. Preparing in advance is the best way to restore normal service operations as quickly as possible.