Operations | Monitoring | ITSM | DevOps | Cloud

The Place Where Modern Operations & Technology Come Together


#027 - Kubernetes for Humans Podcast with Ben Sigelman (ServiceNow)
Ben Sigelman is the General Manager of ServiceNow Cloud Observability, which solves for the reliability and performance of cloud and cloud-native applications while broadening the scope and leverage of the broader Now Platform. Previously, he co-founded and was CEO of Lightstep, which ServiceNow acquired in 2021, and co-created both the OpenTracing and OpenTelemetry projects. Ben also helped define modern observability with his work on tracing and metrics monitoring at Google (the Monarch and Dapper projects) and was a pioneer in SRE best practices and tooling.

#026 - Kubernetes for Humans Podcast with BJ Badyk (Nexxen)
BJ Badyk is a human who desires an easier life. Nerd from birth, his curiosity led him down a path through the start of ISPs, Silicon Valley during the dot-com bubble, the last few years of the Playboy brand, and into the world of Adtech. He currently runs the platform engineering team at Nexxen, where they work on unique ways of handling millions of requests per second with Kubernetes. The team was an early adopter of Talos Linux, which they now run at scale. He presented at TalosCon 2023 and continues to pursue simple solutions to complex problems.

#025 - Kubernetes for Humans Podcast with Ashan Senevirathne & Joel Studler (Swisscom)
Ashan Senevirathne is an experienced Product Owner and Senior DevOps Engineer with a proven track record in driving innovation and efficiency in telecommunications. Currently with Swisscom, leading the development of a cloud-native orchestration framework for 5G Core using Kubernetes. Adept at optimizing release engineering processes, championing CI/CD workflows, and fostering cross-functional collaboration. Recognized for his expertise in Kubernetes, GitOps, cloud-native principles, and network orchestration.

#024 - Kubernetes for Humans Podcast with Gabriele Bartolini [EDB]
A long-time open-source programmer and entrepreneur, Gabriele has a degree in Statistics from the University of Florence. After having consistently contributed to the growth of 2ndQuadrant and its members through nurturing a lean and DevOps culture, he is now leading the Cloud Native initiative at EDB.
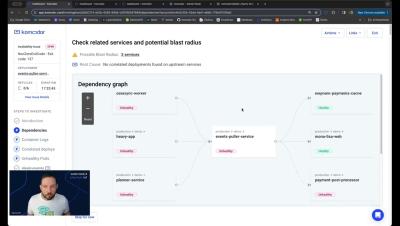
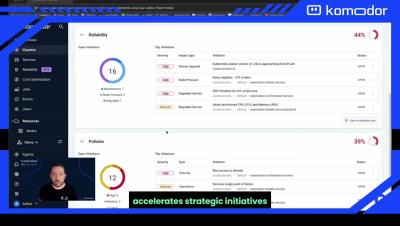
Introducing Komodor's Automated Troubleshooting Co-Pilot
Arthur Enright, Senior Solution Engineer, demoing Komodor's guided troubleshooting experience.
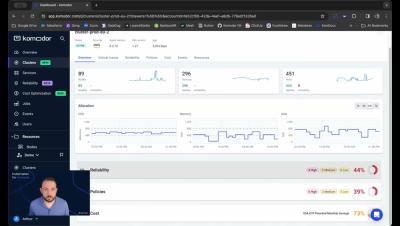
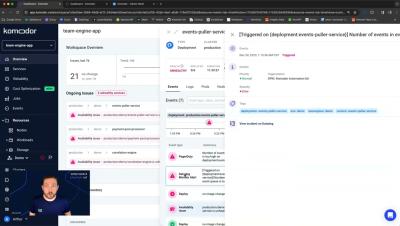
Introducing Komodor's Clusters Dashboard
Arthur Enright, Senior Solution Engineer, presenting Komodor's mission control for platform teams - the clusters dashboard.

#023 - Kubernetes for Humans Podcast with Liz Rice (Isovalent)
Special KubeCon EU 2024 Episode! She has a wealth of software development, team, and product management experience from working on network protocols and distributed systems, and in digital technology sectors such as VOD, music, and VoIP. When not writing code, or talking about it, Liz loves riding bikes in places with better weather than her native London, competing in virtual races on Zwift, and making music under the pseudonym Insider Nine..

#022 - Kubernetes for Humans with Adrian Cockcroft (Nubank)
Adrian Cockcroft has played an instrumental role in shaping the modern cloud computing landscape, particularly through his contributions at Netflix and later at Amazon Web Services (AWS). With a background in computer science, Cockcroft’s career has spanned various roles, including developer, architect, and executive positions, where his insights into scalable, resilient systems design have had a profound impact.