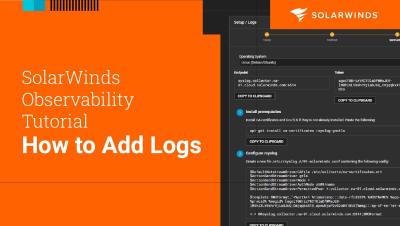
Introduction to AWS Observability in Grafana Cloud | Grafana
Grafana Cloud's streamlined approach to collecting and configuring your AWS data makes it easier to manage your cloud environment and improve performance. ☁️ Grafana Cloud is the easiest way to get started with Grafana dashboards, metrics, logs, and traces. Our forever-free tier includes access to 10k metrics, 50GB logs, 50GB traces and more. We also have plans for every use case.