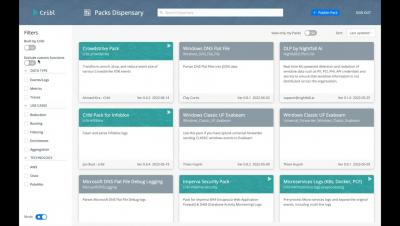
Cribl Pack Dispensary Walkthrough
The Pack Dispensary is the best place to find and download the latest Cribl Packs from the Cribl Community.


Cribl Packs are, in my opinion, our most exciting feature. Packs encapsulate the deep log processing capabilities and enable sharing of the best practices with customers, Worker Groups/Fleets, and the Community. Ease of sharing enables consistent configurations across distributed deployments of Cribl Stream or Cribl Edge. All users can leverage Packs–and should! If you collect Microsoft Windows Logs, use Palo Alto Networks or share logs via Syslog, Packs are for you.
Every enterprise collects and stores massive amounts of security and observability data but struggles to get value outside of operations and security teams. These datasets can offer enormous value to business operations and enterprise reporting teams if they have access to the data in their toolsets. BizOps needs to optimize batch planning and the enterprise reporting teams need to reconcile how many assets the enterprise owns versus the number it has under support contracts.
Back in late May, we hosted a webinar on the heels of our Series D funding announcement where we also took the wraps off our big product announcement: Cribl Search.
Software exists to make your job easier, not to suck the joy out of your work. It should be there when and if you need it, but be completely out of the way when you don’t — you’re at work to get a job done, not to use any particular product. If you’re forced into using the same underperforming, over-customized, difficult to implement, or just generally terrible software each and every day, it can really put a damper on the quality of your work and quality of life.
If there was a question on if an enterprise needed an observability pipeline in 2019 or 2020, we now know the answer is: yes. The observability data management methods of the 2010s aren’t going to work in the 2020s. Data is growing too fast for us to ignore, and the need to gain intelligence from said data continues to grow in importance. Data (and access to it) is becoming a competitive edge for many enterprises today.
An old colleague of mine once said to me, “It doesn’t matter how inefficiently something DOESN’T work.” This was a joke used to make a point, so it stuck with me. It also made me consider that it does matter how efficiently something DOES work. Sometimes, when we have tools like Cribl Stream making things like routing, reducing, and transforming data so easy, we can forget that there might be a more efficient way to do it.
Git integration has always been at the foundation of Stream. In the fall 2021 release of Cribl Stream (both on-prem software and Cloud), our Enterprise users have a received set of APIs to separate the development and deployment of Stream. Stream GitOps connects with your favorite git based versioning platforms and leverages their PR, approve/reject, and CI/CD workflows to push production-ready changes from a development branch into a main branch or release.
It’s been an exciting few days at Cribl. A week ago, we announced our $150 Million Series D funding round led by Tiger Global, with participation from existing investors IVP, CRV, Redpoint Ventures, Sequoia Capital, and Greylock! We also announced an exciting new product: Cribl Search! We’ve been blown away by the excitement from our customers thus far.