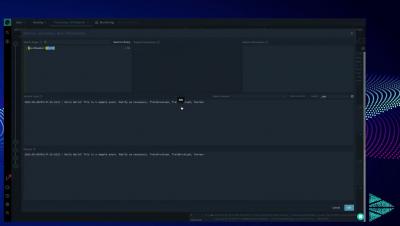
Masking Data with Cribl Stream
With Cribl Stream, you can mask data using a variety of techniques by applying the Masking Function on any event that matches any arbitrary condition. This feature is especially useful for redacting PII (personally identifiable information) and other sensitive data.