

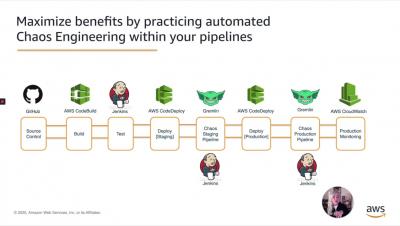
Chaos Engineering: How to create an automated Chaos Gauntlet with Gremlin and Jenkins on AWS
In this video, we will demonstrate how to use Gremlin and Jenkins to create an automated Chaos Gauntlet. This will be done using Jenkins Pipelines and Stages to inject a controlled amount of failure with the Gremlin API. We then add a final stage that allows you to optionally halt the attack from the pipeline, rather than having to wait for the full duration of the attack.








