

How Detected Risks helps you find reliability risks in minutes-without running any tests
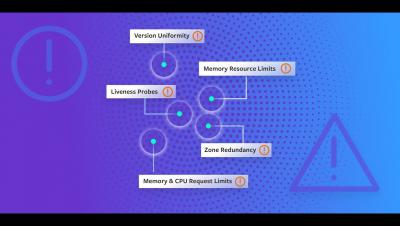
This video showcases Gremlin's Detected Risks feature. Detected risks are high-priority reliability concerns that Gremlin automatically identifies in an environment. These include misconfigurations, bad default values, and reliability anti-patterns. Gremlin prioritizes these risks based on severity and impact, giving instantaneous feedback on risks and action items to improve the reliability and stability of each service.








