Virtual Meetup: SIEM 101: What, Why & How of Information Security
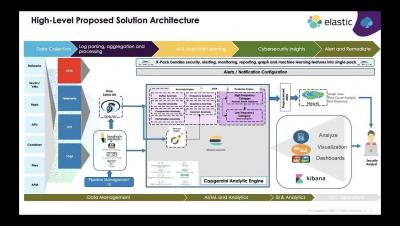
SIEM abbreviated as Security Information & event management plays an important role in an organization's information security posture.


As Elasticsearch users are pushing the limits of how much data they can store on an Elasticsearch node, they sometimes run out of heap memory before running out of disk space. This is a frustrating problem for these users, as fitting as much data per node as possible is often important to reduce costs. But why does Elasticsearch need heap memory to store data? Why doesn't it only need disk space?
Let’s be honest. No one wakes up in the morning thinking of reasons to contact customer support. It’s tedious, onerous, and can eat into your evening Netflix time. Thankfully, most brands realize that customer experiences drive brand loyalty and repeat purchases.
Binary classification aims to separate elements of a given dataset into two groups on the basis of some learned classification rule. It has extensive applications from security analytics, fraud detection, malware identification, and much more. Being a supervised machine learning method, binary classification relies on the presence of labeled training data that can be used as examples from which a model can learn what separates the classes.
If you want to skip ahead to see the MITRE ATT&CK eval round 2 results visualized in an easy-to-configure Kibana dashboard, check it out here.
To achieve unified observability, we need to gather all of the logs, metrics, and application traces from an environment. Storing them in a single datastore drastically increases our visibility, allowing us to monitor other distributed environments as well. In this blog, we will walk through one way to set up observability of your Kubernetes environment using the Elastic Stack — giving your team insight into the metrics and performance of your deployment.