Operations | Monitoring | ITSM | DevOps | Cloud


Machine Learning
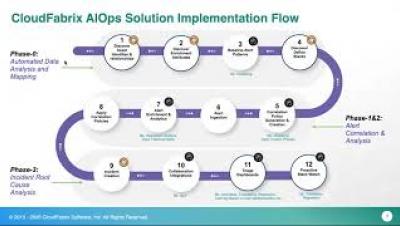

How to Automate the End-to-End Lifecycle of Machine Learning Applications
Machine Learning (and deep learning) applications are quickly gaining in popularity, but keeping the process agile by continuously improving it is getting more and more complex. There are many reasons for this, but primarily, behaviors are complex and difficult to anticipate, making them resistant to proper testing, harder to explain, and thus not easy to improve.

Predicting and Preventing Crime with Machine Learning - Part 2
In the first part of this blog series, we presented a use case on how machine learning can help to improve police operations. The use case demonstrates how operational planning can be optimized by means of machine learning techniques using a crime dataset of Chicago. However, this isn’t the only way to predict and prevent crime. Our next example takes us to London to have a look at what NCCGroup’s Paul McDonough and Shashank Raina have worked on.

Kafka Data Pipelines for Machine Learning Enterprise Applications
Traditional enterprise application platforms are usually built with Java Enterprise technologies and this is the case as well for OpsRamp. However, in machine learning (ML) world, Python is the most commonly used language, with Java rarely used. To develop ML components within enterprise platforms, such as the AIOps capabilities in OpsRamp, we have to run ML components as Python microservices and they communicate with Java microservices in the platform.

Distributed Machine Learning With PySpark
Spark is known as a fast general-purpose cluster-computing framework for processing big data. In this post, we’re going to cover how Spark works under the hood and the things you need to know to be able to effectively perform distributing machine learning using PySpark. The post assumes basic familiarity with Python and the concepts of machine learning like regression, gradient descent, etc.

BDA Europe 2019: How Do You Monitor 100% of Your Data While Asleep?

Use Kubernetes to Speed Machine Learning Development
As industries shift to a microservices approach of deploying applications using containers, data scientists can reap the benefits. Data Scientists use specific frameworks and operating systems that can often conflict with the requirements of a production system. This has led to many clashes between IT and R&D departments. IT is not going to change the OS to meet the needs of a model that needs a specific framework that won’t run on RHEL 7.2.

ML and AI enabled IT Ops: the NOC as a modern cockpit
A common sentiment among our prospects after they see our demo for the first time is: “That’s it? It can’t be that simple!”. The truth is – yes it can be, and it should be. ML and AI should make IT Ops simpler, and a big part of that is usability. If your ML & AI powered IT Ops tools take months to set up and weeks to learn, and then don’t provide a substantially improved user experience, you’re obviously using the wrong tools.
Deploy Your First Deep Learning Model On Kubernetes With Python, Keras, Flask, and Docker
This post demonstrates a *basic* example of how to build a deep learning model with Keras, serve it as REST API with Flask, and deploy it using Docker and Kubernetes. This is NOT a robust, production example. This is a quick guide for anyone out there who has heard about Kubernetes but hasn’t tried it out yet. To that end, I use Google Cloud for every step of this process.