How to Build a Service Catalog in 5 Easy Steps
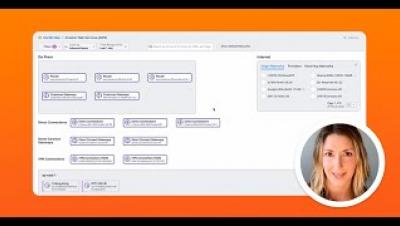
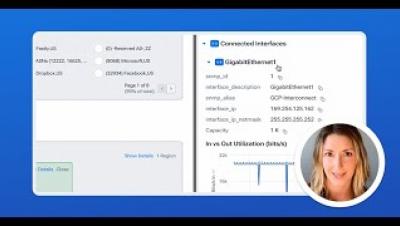
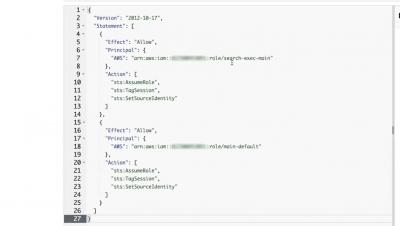
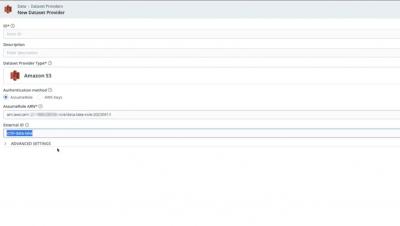
Building a service catalog is an absolute must to improve your company's IT self-service — and you can do it in just five simple steps! An ITIL service catalog benefits the business, consumers, and IT organizations alike, since it: In this video, InvGate Product Specialist Matt Beran walks you through creating a service catalog on InvGate Service Desk and highlights its differences from a service portfolio.