Kubernetes Master Class: GitOps, Rancher and ArgoCD with Codefresh
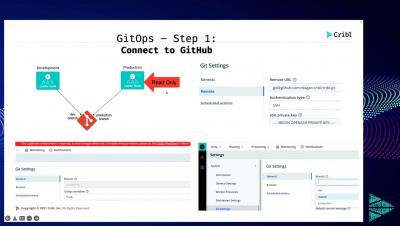
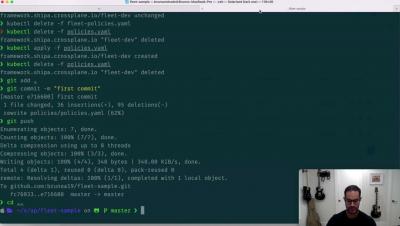
Join Robert Sirchia and Dan Garfield for this session. Configuration drift is a common problem software developers face. Picture this: two environments are supposed to be similar but are not. Nobody knows exactly what is deployed in that environment/server/cluster, so people are afraid to touch it. It’s declared “off-limits” because nobody can reconstruct it if it breaks down. People do hot-fixes or ad-hoc changes without recording them, and then those developers change teams or companies.