

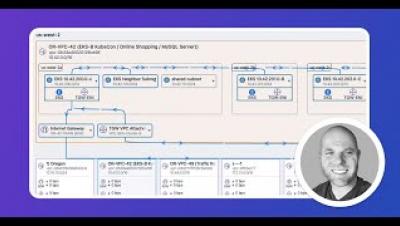
Kentik Kube: Container Network Performance Monitoring
In this brief demo, Phil Gervasi explains how you can use Kentik Kube to monitor K8s network performance among your containers on-premises and in public cloud. With Kube, you can get granular visibility into container performance in terms of packet loss, packet size, protocol and application activity, TCP flags, and network latency.











