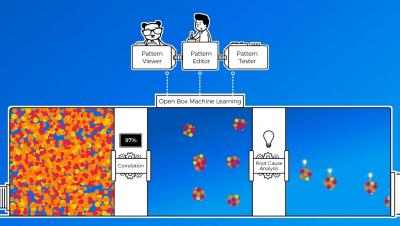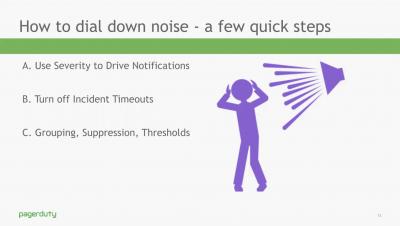
Optimize Your Services to Save Time, Money, and Sleep - July 2019
Interested in how to tune-up your services to derive even more benefit from your PagerDuty implementation? Easy and simple changes can have a huge impact on how much time and money you spend.