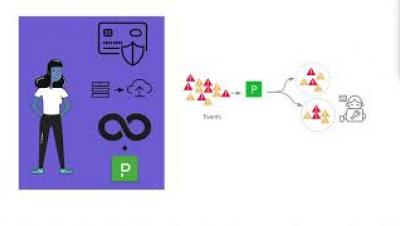
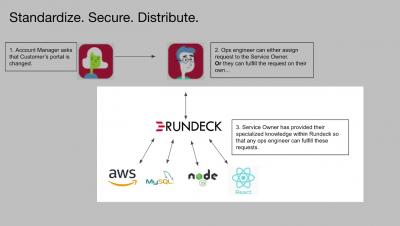
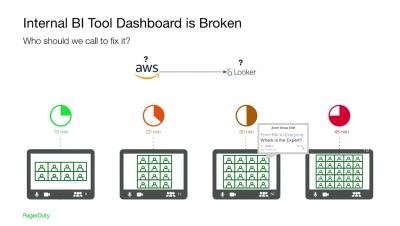
Cloud cost management with Looker
If you’ve ever been surprised by the invoice from your cloud provider, then this video is for you! In this episode of Data Science & Analytics Patterns, we talk about managing your cloud costs by exporting billing data into your data warehouse and analyzing it with Looker.