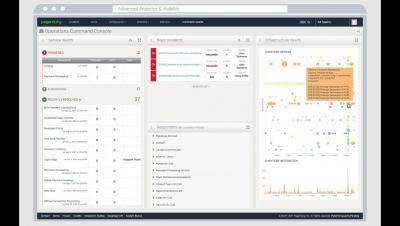
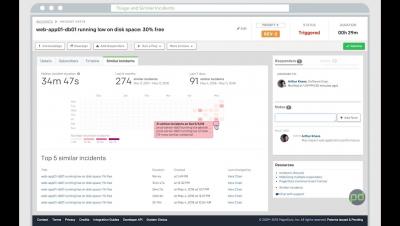
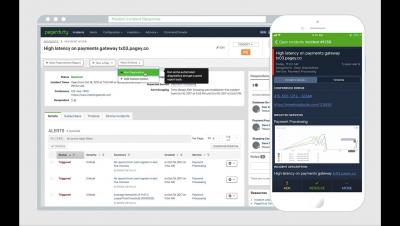
IDC Report: Less Than 5% of All Data Analyzed
The global data supply reached 4.4 zettabytes (ZB) in 2013 – or 4.4 trillion GB – but less than five percent of that data was actually analyzed, according to the seventh Digital Universe report by the IDC. Approximately 22 percent of all existing data would actually be useful if tagged and analyzed.