

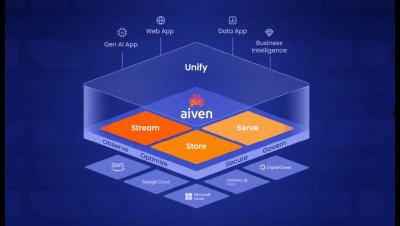
What is the Aiven Platform?
Your Trusted Data and AI Platform. Aiven is a platform that optimizes data and AI workloads across multiple clouds. It seamlessly integrates with any business size, enabling efficient data management and scaling. With AI-driven optimization, deploy technologies effortlessly to stream, store, and serve your data, focusing on innovation and cost savings.








