Get Automatic Oncall Reports
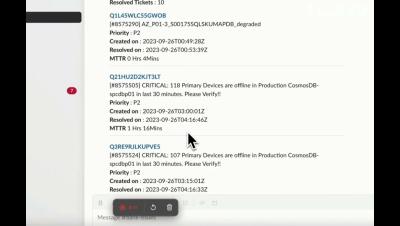
As a Pagerly user, you can easily access the Oncall Summary from PagerDuty and Opsgenie to gather information for your Oncall Handover. This includes the current count, incoming tickets, resolved tickets, and your team's trends. With Pagerly, you can generate your entire Incident Reports during the oncall shift.