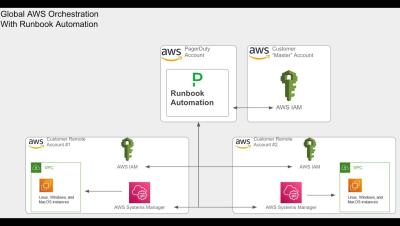
NOC Success Like Never Before: Automation Strategies for All-new Incident Management
Network Operations might never be the same. But then again, why would anyone want it to be? The power of automation and orchestration can bring incredible value to the Network Operations Center (NOC), including the business-critical call to get proactive and ahead of the incidence response and management game. It’s more than a towering volume of events – it’s the complexities involved, too.