Predictions: a Deeper Dive into the Rise of the Machines
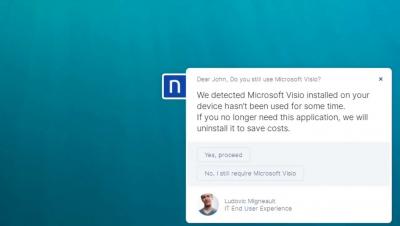
As Gaurav described in his retail predictions blog, the impact of AI and automation on the retail industry should not be underestimated. The compound effects of improvements in technology and labour shortages have created an ideal scenario for innovation. Here we will take a deeper look into some of the AI and automation use cases that we have seen in retail and outline some of the areas of focus to help you get started.