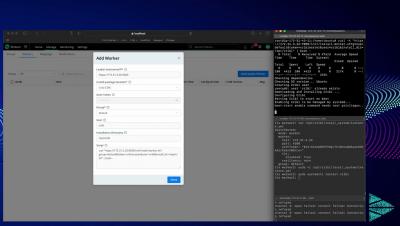
Observability trends and challenges in 2023
Hear from Corneile Britz, Observability and DevOps Specialist and Co-Founder of Boxfish his Observability predictions for next year Speakers: Jag Dhillon, Grafana, Solutions Engineer (APAC), Corneile Britz, Boxfish, Co-Founder and Observability Devops Specialist