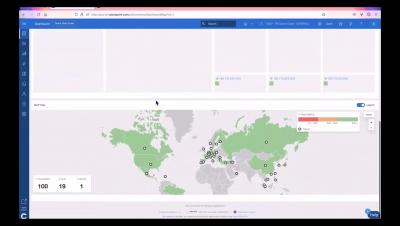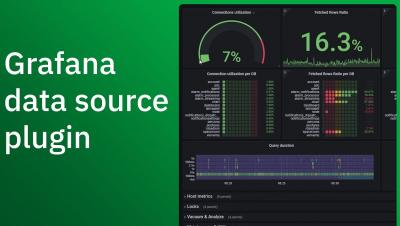
Introducing the new data source plugin for Grafana
When Netdata's metric collection meets Grafana's visualization capabilities, you get powerful and dazzling dashboards to strengthen your monitoring infrastructure. Hugo Valente, Senior Product Manager, walks through the new plug-in to be sure that you're making the most of this unbeatable combination.