Sponsored Post

Real User Monitoring best practices
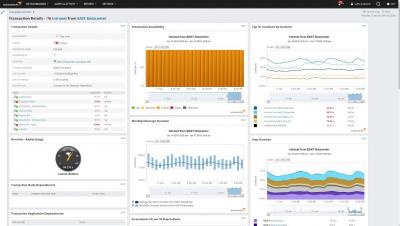
Customer experience is becoming a key differentiator between competitors. Actually, it already is! If your website is performing poorly, it's hurting your business. The first step towards improving this performance is using a real user monitoring tool to identify problems and monitor your progress towards improvement.