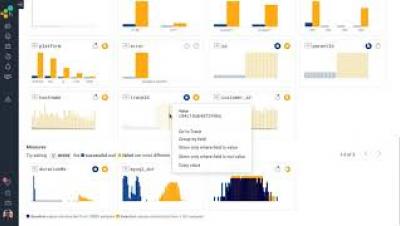
Driving Real-Time ChatOps With PagerDuty and Microsoft Teams
With over 75 million daily active users, it’s safe to say Microsoft Teams is essential to many global businesses. On top of that, Microsoft CEO Satya Nadella recently shared that Microsoft saw 200 million meeting participants in a single day this month. While Microsoft Teams’ explosive growth can be tied to recent spikes in remote work, many enterprises have relied on Teams to connect people across the globe for quite some time.