Leading provider of digital, cloud and advisory services reduced time-to-resolve issues by 1400% with VirtualMetric
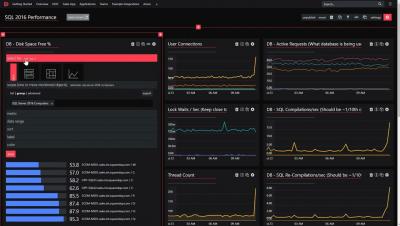
A leading provider of innovative digital and cloud services, part of the Microsoft ecosystem, chose VirtualMetric to get critical insights and complete visibility over their cloud environment. With 38,000 professionals in 24 countries, the company is specialized in cloud and application services, managed services, analytics, AI and helps companies to implement the latest technologies to various industries, leveraging the Microsoft platform.