Debug application issues with APM and Network Performance Monitoring
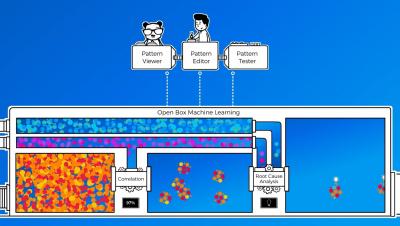
With the advanced containerization that has become the norm in the modern cloud, your infrastructure is likely more distributed, and thus more exposed to networking issues, than ever before. When troubleshooting application performance issues, this can make it difficult to link the symptoms you observe through monitoring the “golden signals” (requests, latency, and errors) on individual endpoints in your application to their underlying root causes.