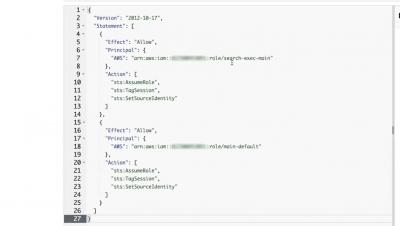
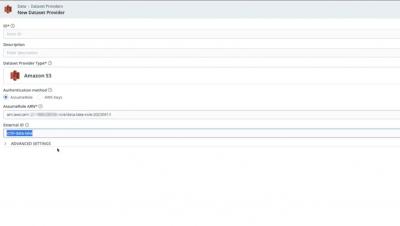
Microsoft Outlook on the web Outage, June 6th, MO572252
Yesterday’s Microsoft 365 Suite-wide outages, led to continual faults for Outlook on the web on Tuesday, June 6th. When the outages pile up, it becomes difficult to tell when one starts and the other ends. The latest: Can’t access Outlook on the web and other Microsoft services and features The prior day incidents began with EX571516: Some users are unable to access Outlook on the web, and may experience issues with other Exchange Online services.