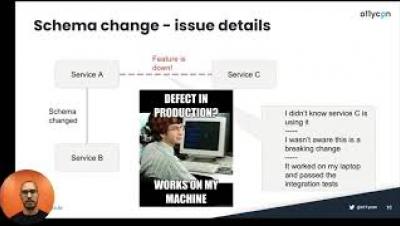
What's new in Grafana Cloud for July 2021: Traces, live streaming, Kubernetes and Docker integrations, and more
If you’re not already familiar with it, Grafana Cloud is the easiest way to get started observing metrics (Prometheus and Graphite), logs (Grafana Loki), traces (Grafana Tempo), and dashboards. Here are the latest features you should know about!