DataDog vs Prometheus - Comprehensive Comparison Guide [2025]
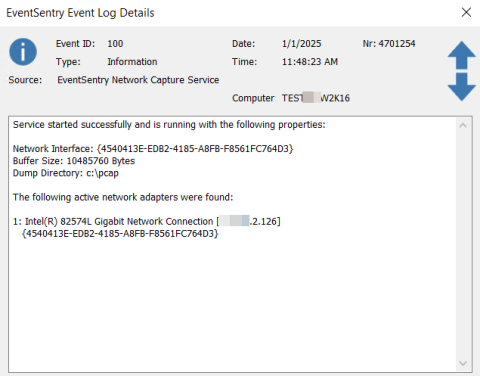
Both DataDog and Prometheus are application monitoring tools aimed to improve application performance. While Datadog is a cloud-based SaaS solution, meaning there's no need to install or maintain any infrastructure, Prometheus is an open-source tool that requires manual download and installation on your infrastructure. Let us compare DataDog and Prometheus to see which tool suits The biggest difference between Datadog and Prometheus is that while Prometheus is open-source, Datadog is proprietary.