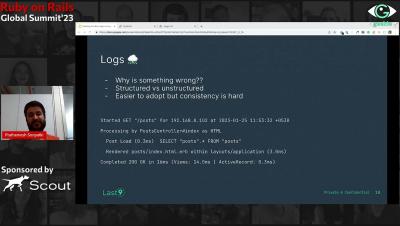
How to achieve distributed tracing using Application Insights?
In this blog, we will explore how distributed tracing works in Application Insights and how to use it to diagnose the issues in a distributed application. Azure Application Insights is a powerful tool for monitoring and diagnosing application performance issues and supports distributed tracing. It is an extension of Azure Monitor and provides Application Performance Monitoring features out of the box.