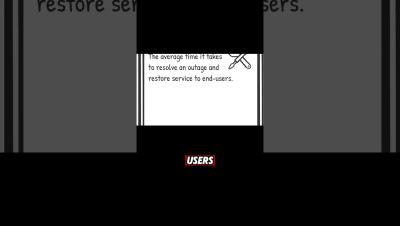
What is SLA (Service-Level Agreement)?
Service level agreements (SLAs) are essential for defining and managing the performance of services provided by internal or external providers. This article explores the different types of service agreements, their key components, and best practices for creating and enforcing effective agreements.