JFrog & Splunk - Observability for your IT Value Stream
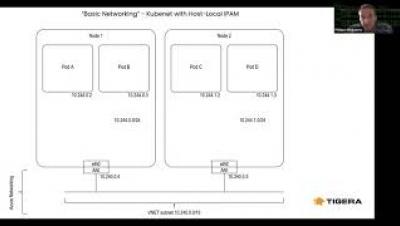
As software is the product in many of today's businesses, the need to manage the value stream from development to production is critical to ensure consistency of information, compliance and supply chain collaboration.In order to consistently deliver high velocity and quality of applications, engineering teams require visibility into how code is moving from dev to prod in a stable and efficient manner. Just as Observability is changing the way teams managing their applications in production, the concepts of observability apply to the entire software value stream.