Monitoring and incident management: a winning combination
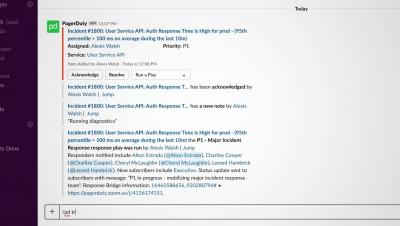
Monitoring systems gather and log a wide range of performance data on a diverse range of targets—from applications to user experience, networks, servers, and more. Usually, monitoring is conducted under runtime conditions, but synthetic monitoring can also be used to simulate loads and test the resilience of web services, for example.