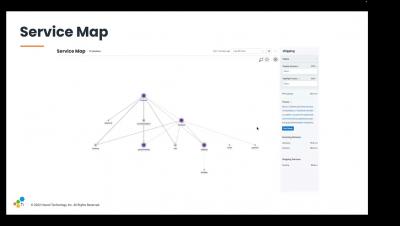
Elastic Observability: Built for open technologies like Kubernetes, OpenTelemetry, Prometheus, Istio, and more
As an operations engineer (SRE, IT Operations, DevOps), managing technology and data sprawl is an ongoing challenge. Cloud Native Computing Foundation (CNCF) projects are helping minimize sprawl and standardize technology and data, from Kubernetes, OpenTelemetry, Prometheus, Istio, and more. Kubernetes and OpenTelemetry are becoming the de facto standard for deploying and monitoring a cloud native application.