

How to Implement Network Policy in Amazon EKS to Secure Your Cluster
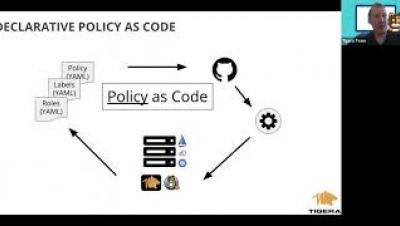
By default, pods are non-isolated; they accept traffic from any source. The Amazon EKS solution to this security concern is Network Policy that lets developers control network access to their services. Amazon EKS comes configured with Network Policy using Project Calico which can be used to secure your clusters. This class will describe a few use cases for network policy and a live demo implementing each use case.








