Stronger together: (Agentic) AIOps and observability are the keys to IT resilience
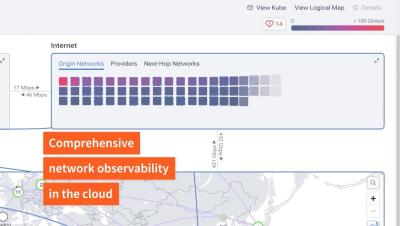
Every new layer of infrastructure piles onto an already fragile web of interconnected challenges, making it painfully clear: traditional monitoring can’t keep up. You’re drowning in alerts, buried in data, and yet somehow still flying blind when real issues arise. More notifications don’t mean more insight, and more data doesn’t guarantee better decisions.