The SIGNL4 mobile app
Brief overview of the functions of the SIGNL4 mobile app


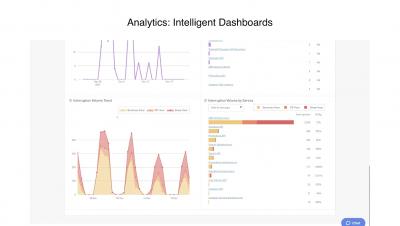
The latest News and Information on Incident Management, On-Call, Incident Response and related technologies.
After two years of sky-high spending on cloud and related technologies, 2022 is the crunch point for corporate IT and digital leaders. Investments in technology helped facilitate the rapid shift to mass hybrid working and supported businesses to embrace the digital-first models of the new normal. But beyond merely investments to support new working styles, leaders also must ensure their organization continues to innovate.
Workflows are no stranger in the DevOps world. But where did this term come from, and what does it really mean? Perhaps it’s no surprise that workflows originated from the industrial revolution, which brought powerful machinery for mobilizing huge workforces unlike ever before. To maximize the potential of these new industrial tools, people had to first figure out the best way to use them to get work done as efficiently as possible.
At PagerDuty, we are committed to championing the customer — it’s a core company value. Our product has to provide great value, we have to provide excellent service, and we need to make it simple to do business with us. The Winter 2022 G2 Grid for AIOps Platforms Relationship Index showcases these values and highlights PagerDuty as a leading player in the AIOps space.
I am excited to announce today that BigPanda has secured $190 million in financing at a $1.2 billion valuation. This financing was led by Advent International and Insight Partners, together with our other existing investors. BigPanda is now officially a unicorn, and the clear leader in the rapidly growing AIOps market!